1. 町丁目別統計データの取得 Nov. 2, 2012
2.QGISで表示と属性データの編集 Nov. 4, 2012
3. 属性テーブルの結合 Nov. 14, 16, 2012
4. e-statの境界データに男女・年齢別人口csvを結合する例 Nov.17-19, 2012
5. 残りの時間にできること Nov. 22, 2012
6. e-stat のcsvファイルをエクセルで分析 Nov. 27, 2012
7. コロプレスマップ階層区分図を表示する Jan. 05, 2013
8. QgisからGrassへのシェープファイル出力 Jan. 1, 2013
http://www.e-stat.go.jp/SG1/estat/eStatTopPortal.do
で,町丁目別統計データの取得が可能である。このトップページから,地図で見る統計(統計GIS)
を選び,データダウンロードをクリック,
統計表検索(ダウンロード用)が表れる。
http://www.e-stat.go.jp/SG2/toukeichiri/TopFrame.do?fromPage=init&toPage=download
ここでは,
平成22年国勢調査(小地域)
2010年農林業センサス(農業集落単位)
平成18年事業所・企業統計調査-世界測地系(1km, 500mメッシュ),などがある。
このうち一例として,平成17年国勢調査(小地域)2005/10/01を利用する。
小地域とは町丁目別のものである。同ページの右のペーンに,男女別人口総数および世帯総数,年齢別・男女別人口,世帯人員別一般世帯数,住宅の建て方別世帯数,職業別就業者数などの統計表がある。ここでは,職業別(大分類)就業者数を選択して,次へ。
統計表各種データダウンロードの画面が出る,この左のペーンで大阪府吹田市(27205)を選ぶ。
右のデータダウンロードのペーンで,上段の,吹田市(6kB)をクリック。一瞬でダウンロードされ,csvテキストが自動的に表示される。これをデスクトップに保存して,エクセルから読み込んで,区分記号をカンマとすると,表形式で表示される。なお,このテキストはShiftJISコード(CR+LF(Win))で記述されている。ここをクリック
この表の列名は英字のために,このままdBaseIIIファイルにできるが,ポリゴンとの対応関係が付かないので,手作業でのマッチングをしないといけない。下記のように,第2行には職業別区分名が示されている。
| KEY_CODE | HYOSYO | HTKSYU | CITYNAME | NAME | T000150001 | T000150002 | T000150003 | T000150004 | T000150005 | T000150006 | T000150007 | T000150008 | T000150009 | T000150010 |
| 職業別15歳以上就業者 | A専門的・技術的職業従事者 | B管理的職業従事者 | C事務従事者 | D販売従事者 | Eサービス職業従事者 | F保安職業従事者 | G農林漁業作業者 | H運輸・通信従事者 | I生産工程・労務作業者 |
ここで示したcsvファイルをdBaseIII (OpenOffice Base)で編集するのは結講面倒な作業になる。限界はあるが,幸い,上記ページの,Step 4: データダウンロードで,右のペーンの境界データのうち,世界測地系平面直角座標系・shape形式をダウンロードしてみよう。次の節では,この操作について示す。
この節での作業は次のサイト以下を参考にして実行してください。
地理情報システム学2の左のペーンの,授業内容をクリックして,メーンページに表示されるコンテンツのうち,市吹田市の職業別(大分類)就業者数のデータを使って実行してください。
なお,コロプレスマップchoroplethmapとは,領域で観測されたデータをカテゴリ区分して,領域にそれぞれ固有のパターンや色で表現する統計地図のことである。Grassでの表現は可能ではあるが,面倒な過程を踏む必要があり,この種の表現やそのための属性処理にはQGISが優れている。下記の教材は,ぼくの授業の主旨と合わないところも多く,適宜変更して利用する。
要するに,QGISは簡便なデジタルマップの表示ツールで,GRASSと連動することで,とくに,属性テーブルの編集で非常に有効なツールと言える。
2010-10-14:Q-GISで三重県地図の表示
QGISが如何に簡単に地図の取り込みと表示
2010-10-28:Q-GISにおけるベクターデータの取り扱い
ベクトルマップの属性テーブルの表示
2010-11-4:Q-GISの地図をより見易く
表示の基礎
2010-11-11:新津市全体の人口密度のコロプレスマップを作る
属性テーブルの編集,計算式入力のバグ(演算記号は1回のみ)
2010-11-18:コロプレスマップを見やすくする
クラス分け
2010-12-16:数値標高データ(DEM)及び点に対するバッファリング
数値標高データの取り込みと表示(経緯度座標系)
既存dbfファイルにcsvファイルの列データを追加できる。すなわち,たとえば上の職業別(大分類)就業者数のデータはcsvファイルなので,基盤情報のシェープファイル群のdbfファイルに追加できるのである。種々の属性列データをエクセルで計算処理してその結果をcsvファイルに変更して既存dbfファイルに追加することが可能である。QGISの計算機能にはバグがあり,現在のv.1.8.0ではほとんど使い物にならない。
結合させるには,共通の列データが必要である。ポリゴンのID番号など。qgisは取り込まれるcsvファイルのデータをすべて,テキストにしてしまうので,結合がうまく行かない場合がある。そこで,csvtファイル(すぐに後述)が必要となる。csvファイルの列データが文字データか数値データなのかなどの情報をqgisは取得しない。qgisは元のデータが何であってもすべて文字データにしてしまう。そこでcsvファイルとともに,csvtファイルをcsvファイルと同じフォルダに入れておく必要がある。下に示した,参考になるリンク2からそのまま引用する。テキストエディタで記述してcsv形式で保存し,拡張子をcsvから,csvtに変更するのである。
http://www.gdal.org/ogr/drv_csv.html に書式が掲載されている。その部分を下に引用する。
Limited type recognition can be done for Integer, Real, String, Date (YYYY-MM-DD), Time (HH:MM:SS+nn) and DateTime (YYYY-MM-DD HH:MM:SS+nn) columns through a descriptive file with same name as the CSV file, but .csvt extension. In a single line the types for each column have to be listed: double quoted and comma separated (e.g., "Integer","String"). It is also possible to specify explicitely the width and precision of each column, e.g. "Integer(5)","Real(10.7)","String(15)". The driver will then use these types as specified for the csv columns.
で,最も初心者に役立つのは次のサイトである。
QUANTUM GIS WORKSHOP http://maps.cga.harvard.edu/qgis/wkshop/join_csv.php
他の参考になるリンク:
リンク1 空間情報システム演習 Q GIS入門(1) http://www.slideshare.net/hiroakisengoku/qgislecture-1
このプレゼンファイルは90 pagesからなる。-2以下の教材は無いようである。このファイルで特に,属性テーブルの操作 p.52-,編集 p.66-,結合 p.72-,フィールドの削除・並べ替え p.78-,フィールド演算 p.80-84,を見ておくこと。
リンク2 属性テーブルの検索と操作: GISデータのもう一つの中核である属性テーブルについて
を参照すること。特に,csvtファイルについて。
リンク3 Quantum GIS User Guide Version 1.6.0 ’Copiapó’http://docs.osgeo.jp/foss4g/qgis/user_guide-1.6.0/user_guide.htmlも参考になる。
なお,吹田市のe-statデータを利用して,何を求めたいのか,まずは考えて,エクセルでの計算処理を実施して,そして,既存シェープファイルに結合しなさい。結合の方法を理解してもらうために,一例を示す。ただ,ここでは,分析目的を全く考えずにただ既存のデータで実施しているので,君たちはエクセルやOpenOffice Calcでの分析結果をcsvファイルとしなさい。
ここでは吹田市のデータのうち,まずはシェープファイルで用意された
目的:Qgis上で,吹田市の「境界データ」という基盤シェープファイルに吹田市のcsvファイル「男女別人口総数及び世帯総数」を結合する。
結合まえに:
前者の属性テーブルには,面積など38列が用意されている。この中で,最後の第38列は,KEY_CODEで,これは定義書を見ると,図形と集計データのリンクコードとなっている。備考には,KEN+KEYCODE2とある。KENは第5列で都道府県番号,KEYCODE2は第16列にあり町丁・字等別結果マッチング番号。
後者のcsvファイルにも定義書が用意されているがここには前者のような詳細は無い。直接csvファイルを見る必要がある。第1列にKEY_CODE列が配置されている。以下,種々の情報が掲載されている。つまり,境界データ,と,種々の主題csvファイル,とは結合して使うことを意識したものになっている。以下の作業のなかで,必要なので,構造を示すと,KEY_CODE,HYOUSHO,HTKSYU,CITYNAME,NAME,そして,男女別年齢別人口であるT000051001~T000051066。
前述のように,csvファイルだけではデータはすべて文字データになってしまうので,csvtファイルを作る必要がある。データ種を見て,OpenOffice Calcで作成したものをテキストエディターで開いたものが次のものである。
"Integer(12)","Integer(2)","String(8)","String(8)","String(16)"以下は「,"Integer(8)"」が66個。66番目の"Integer(8)"の後にカンマは不要。ただただ一行。これには実際は改行記号がないので,一行に長く並ぶ。
このcsvtファイルは,csvファイル「男女別人口総数及び世帯総数」と同じフォルダ(csvファイル1個とcvstファイル1個で計2個)に入れて,拡張子以外をこのファイル名と同じものにしておく。
ところが,かなりのデータがnullになってしまった。この原因を探すのに金曜夜から日曜日24時近くまでかかった。データを詳細に調べたりネットサーフィンをしたが解決の道が見えなかった。csvtファイルを使わなければcsvデータは全部取り込まれるが数値データがすべてテキストデータになってしまう。こういうデフォルト設定になっている。
なお,別件であるが,cvsの行政区画数は219件,ところが境界データつまりポリゴン数は190件にすぎない。csvファイルのレコードが29件使われないことになる。行政区画の変更があったのか定かではない。
マックとWindowsでは改行が異なるなど,Qgis用にファイル変換する場合,注意が必要である。この種の作業をするには,OpenOffice.org Calkが適している。各変数はダブルコーテンション" "で囲む必要があるが,テキストのエキスポートを実行する際に,文字列のエンコーディング,フィールド区切り,テキスト区切り記号(つまりダブルコーテンションなど)を選ぶことができる。そして,セルの内容を表示通りに保存,にチェックを入れること。
ぼくが犯したミスを君たちにトレースさせるのは気の毒なので,csvtの適切な設定値をここに示す。
境界データ,つまり,レイヤを構成しているベクトルデータのdbfまたはQGISで属性テーブルを見ると,csvファイルとの共通のフィールドのKEY_CODEに掲載されている値はすべてセルの左寄せになっている。レイヤプロパティのフィールドで第37列をみるとStringになっている。結合予定のcsvファイルを見ると,共通のフィールドのKEY_CODEの値はすべて右寄せになっている。つまり,数値データである。
ベクトルレイヤのKEY_CODEの値が文字コードだから,csvデータも文字データにしないといけない。csvファイルを操作して数値データを関数を使って変換することは可能ではあるが,これをしても結局意味がないらしい。要するに,csvは触らずに,csvtファイルの第1列の表現を実際のIntegerからStringに換えればいいのである。
"String(12)","Integer(2)","String(8)","String(8)","String(16)"以下は「,"Integer(8)"」が66個。
結合が成功した属性テーブルの結合部分付近を次に示す。ここで,もっとも左の列のKEY_CODEが新たにcsvから取り込まれた列である。csvでは数値であったが左寄せ,つまり文字になっている。T000051001の列から右方のデータは,希望どおり数値データとして取り込まれている。
Qgisでの作業を改めて
1. 両ファイルが入っているフォルダも開いておく。まずは,境界データのシェープファイルが格納されているA00205….XYSWC27205フォルダを,Qgisの左のペーン(レイヤ)にドラッグアンドドロップ。吹田市全域が町丁目境界とともに表示される。
2. メーンメニューで,レイヤー/ベクタレイヤの追加。パネルがでる。ソースタイプのファイル,エンコーディング(日本行政のデータはすべてShift_JIS)を設定。変換元データとして,追加したいcsvファイルをブラウズして選ぶ。ファイルの種類として,カンマ区切りファイル[OGR] (*.csv *CSV),を選ぶ。これでQgisにベクトルレイヤとして取り込まれた。もちろん,これにはマップがない。ベクトルマップではなくベクトルの属性テーブルに過ぎない。
3. A00205….XYSWC27205レイヤ,をダブルクリック。そして,結合タブを開く。このウィンドの左上に配置されている,+,をクリック。ベクタ結合の追加パネルが開く。
4.
レイヤを結合する: csvファイル名。
フィールドを結合する:KEY_CODE(これは境界データの方で既存のベクトルマップ)
ターゲットフィールド:KEY_CODE(これはcsvのもの,つまりターゲットはcsvファイル)
OK, OK
5. 取り込み,または結合の確認:
A00205….XYSWC27205レイヤ,をダブルクリックして,フィールドタブを開く。第37列以降,追加されており,タイプも追加されたものはcsvtで指定したとおりになっている(これが大変だった)。
属性テーブルで確認すると,表示に問題はない。
ぼくの所期の思い通りに授業を進行することが不可能な状況になってきた。方針を変更する。Rの統計解析とGrassとRの連携を指導することは難しいだろう。あと6回か。Qgisではできることが限定されているが,Grassのv.extract替わりに,とにかくQgisを使う最大のメリットである簡便な属性テーブル機能を活用する。さらに,是非,Grassの表示機能を使えるようにしてやりたい。そして,空間解析らしくて学生がダウンロードしてGrassやQgisに取り込んだ現有のベクトルマップとラスターマップ(もう少しの追加的入力が必要だが)を使って実施できるv.rast.stats機能を体験させたい。今後の手順を示す。
1. e-statのcsvで提供されている国勢調査データのうち,個々の学生が興味のある列データを使ってエクセルで何らかの分析をする(分析の際,record IDとのヒモ付けは絶対に混乱させてはならない)。異なるテーマでの町丁目データを使った分析は結局,空間統計解析のあたると考えて良い。なお,互いに異なる地域区分のマップ間での分析は,表計算の手法ではできないのはもちろんで,まさにGrassが必要となる。
分析結果から町丁目レコードをグループ化する。つまり,新たなフィールドつまり列を作って,a b c d ...またはもっと直接的なタイプ名称をラベル名として入力する。
2. 上で得られたエクセルデータのうち,record IDと分析結果を表す列データをcsvで出力し,Qgis上で,境界データベクトルレイヤに結合する。Qgis上でrecordグループの分布を表示する。これそのものが空間分析の成果の一つとなる。
3.Qgis上で,同じラベルのレコードを検索してまとめて,ベクトル出力する。ラベル数だけのベクトルを出力することになる。
4. これを,Grass上で吹田市のLocationに取り込む。
5. v.rast.statsコマンドを使って,個々のラベルに対応するraster,ここではDEMと,それぞれのrecordグループにあたるポリゴン域の高度分布を捉える。これが本格的な空間統計解析の結果である。ただ,recordグループとDEMは,分析の前から対応関係はないと考えられるものである。
例えば植生のポリゴンの高度分布の関係を捉える場合は,意味のある結果が出る。これについては時間があれば,実施したい。
6. この分析プロセスで使うポリゴンデータは,個々のペアによって異なるので,時間があれば発表会を実施したい。この場合,どのように作業をしてきたのかも,再現できるようにまとめて報告する必要がある。
6. e-stat のcsvファイルをエクセルで分析
e-stat から自分が興味が持てるcsvファイルをダウンロードして,エクセルで分析する。これは春学期の授業で君たちが習った手法であるが,追加的手法もあるので,ここに掲載する。
なお,関連ファイルはここからダウンロードできる。圧縮している。4ファイルあり,tblT000150C27205.csvは,ダウンロードして表形式で表したもの,
吹田職業別.xlsは,分析プロセスを4枚のスプレッドシートに表現したもの,
Sub ClassifySpecilalist.docは,
吹田職業別.xlsの3枚目のでつかったvisual basicで作ったマクロの中味,
SpecAdminist.csvは,
吹田職業別.xlsの4枚目のもので,Qgisの境界データに統合するためのcsvファイル。
1. ダウンロードしたcsvファイルを表計算ソフトで読み込んで,改めてcsvファイルで保存する。こうすることで,表形式で見ることができるようになる。ここでは吹田氏の職業別データのうち,専門的職業従事者T000150012と管理的職業従事者T000150013の列データを利用する。
2.
吹田職業別.xls,の,最初のワークシート,を参照してください。第1列は町丁目のKey_codeと第2列のNameと,専門的職業従事者T000150012と管理的職業従事者T000150013の列データの%,が表示されている。行データとしては,吹田市,青山台,などの町丁目のデータをまとめた行はすべて削除した結果がここに示されている。
なお,パーセンテージであるが,青葉台1丁目の専門的・技術的職業従事者は209名で,15歳以上の従事者が1310人だから,%は,新たなセルに,=209/1310*100,とすればよい。セルの書式で小数点以下1桁表示にしている。
3.
このワークシートでは正規性の検定を実施している。この結果では全く正規性がない。君たちはこれをする必要がない。
4. さらにこのワークシートには散布図を示している。これは作成すること。エクセルはラベルとして数値データしか表示できないが,数値を表示することで,場所の特定が可能である。
この散布図に赤囲いで示したように,いくつかに区分することが可能であるが,簡単にはグループ化ができない。そこで,次の作業になる。
5. 次のクラスター分析のワークシートに,その分析結果を示す。グループ化が実現している。ただ,こういった多変量解析の説明をすると時間を食うので,これについては言及しない。
6. 先の%値を正規化する。=(%値-平均)/標準偏差(n-1)で変換する。この結果が,ワークシート正規化に記されている。マイナス値は赤で示している。この結果を文字として表現する。
正規化の意味は,値に基づいた順序づけを行うことで,全体での位置づけを実現することである。-3σ,-2σ,-1σ,+1σ,+2σ,+3σ,を区分値とする。-3σ以下を,extremely low,以降,low, lower, plain, higher, high, extremely highとする。この変換を自動的に実施するために,visual basicで作成することになる。
7. そのプログラムをここに記述する。
Sub ClassifySpecilalist.docに示しているが,再掲する。
Sub ClassifySpecialist()
For I = 1 To 184
If Worksheets("正規化").Cells(I + 2, 5) <= -3 Then
Worksheets("正規化").Cells(I + 2, 7) = "ExtrLowSpec"
ElseIf Worksheets("正規化").Cells(I + 2, 5) > -3 And Worksheets("正規化").Cells(I + 2, 5) <= -2 Then
Worksheets("正規化").Cells(I + 2, 7) = "LowSpec"
ElseIf Worksheets("正規化").Cells(I + 2, 5) > -2 And Worksheets("正規化").Cells(I + 2, 5) <= -1 Then
Worksheets("正規化").Cells(I + 2, 7) = "LowerSpec"
ElseIf Worksheets("正規化").Cells(I + 2, 5) > -1 And Worksheets("正規化").Cells(I + 2, 5) <= 1 Then
Worksheets("正規化").Cells(I + 2, 7) = "plain"
ElseIf Worksheets("正規化").Cells(I + 2, 5) > 1 And Worksheets("正規化").Cells(I + 2, 5) <= 2 Then
Worksheets("正規化").Cells(I + 2, 7) = "HigherSpec"
ElseIf Worksheets("正規化").Cells(I + 2, 5) > 2 And Worksheets("正規化").Cells(I + 2, 5) <= 3 Then
Worksheets("正規化").Cells(I + 2, 7) = "HighSpec"
ElseIf Worksheets("正規化").Cells(I + 2, 5) > 3 Then
Worksheets("正規化").Cells(I + 2, 7) = "ExtrHighSpec"
End If
Next
End Sub
ここで例えば, Worksheets("正規化").Cells(I + 2, 7) の意味は,正規化というワークシートの第 I+2行の第7列のセル,ということである。
For I = 1 To 184
Next
ループは,この中の式をI=1から184まで繰り返すという意味である。
メーンメニューの,ツール/マクロ/Visual Basic Editor を選ぶ。そして,このVisual Basic Editorのメーンメニューから,挿入/標準モジュール,を選び,ここに入力する。
8. Concatenate関数を使って,SpecialistとAdministratorのグループ分けをまとめて示す。=Concatenate(セル表示文字,"_And_",セル表示文字)というように両グループ区分をまとめる。
9. スプレッドシート正規化,から,必要な列をコピーして,あらたなスプレッドシートSpecAdminQにテキストの形でペーストする。このスプレッドシートをcsv出力する。これが,SpecAdminist.csvである。
このcsvを,境界データ,つまり,ベクトルの属性テーブルに追加することになる。
7. コロプレスマップ階層区分図を表示する Jan. 05, 2013
QGISでの表示法を示す。作成済みのqgsファイルを開く。下記。
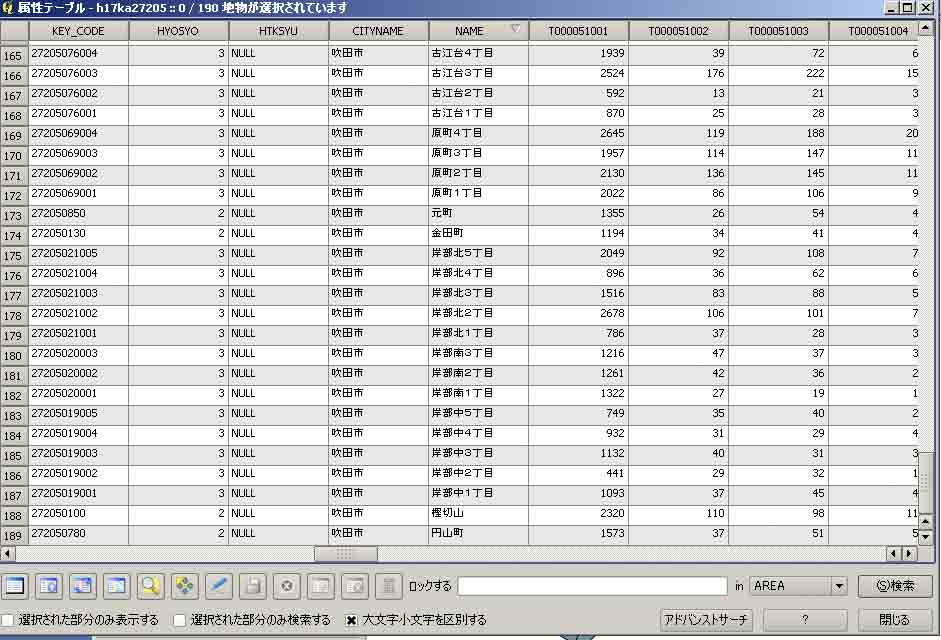
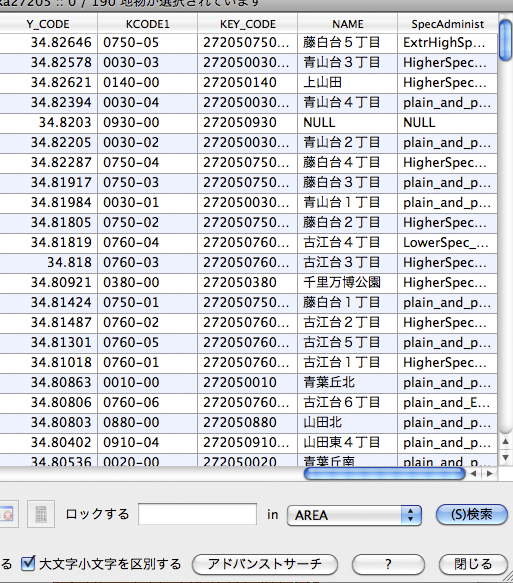
これの属性テーブルを右クリックで開く。Nameに地名が,SpecAdminist(これが新たに追加した計算結果を示す列)に区分が示されている。この区分に従って,階層分布図を作成することになる。
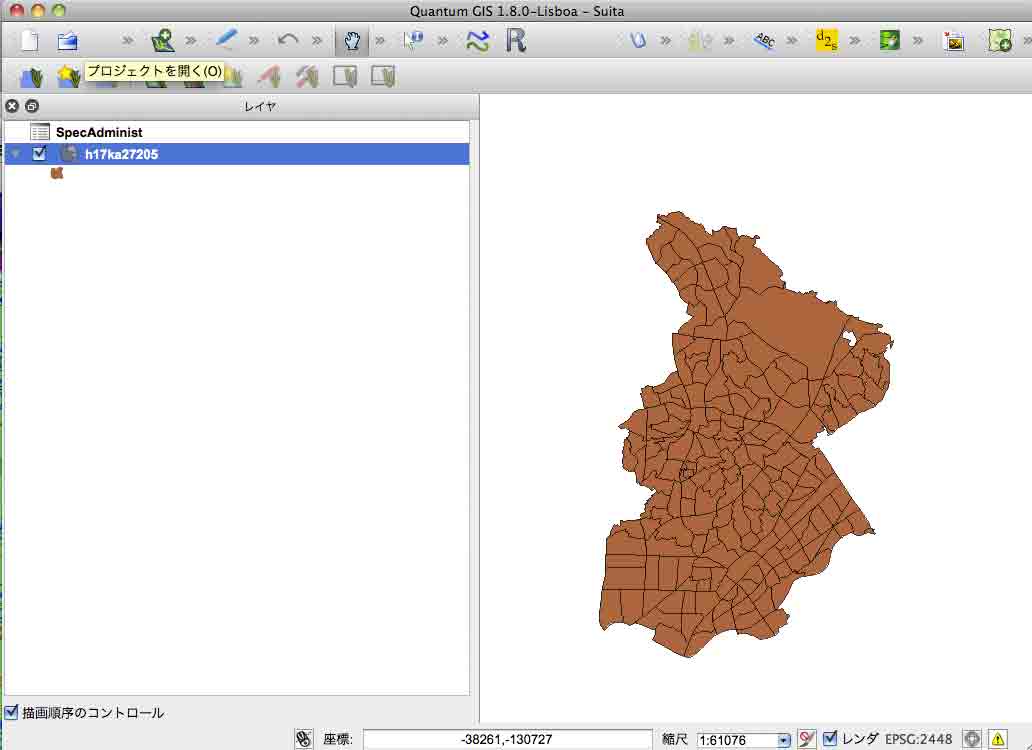
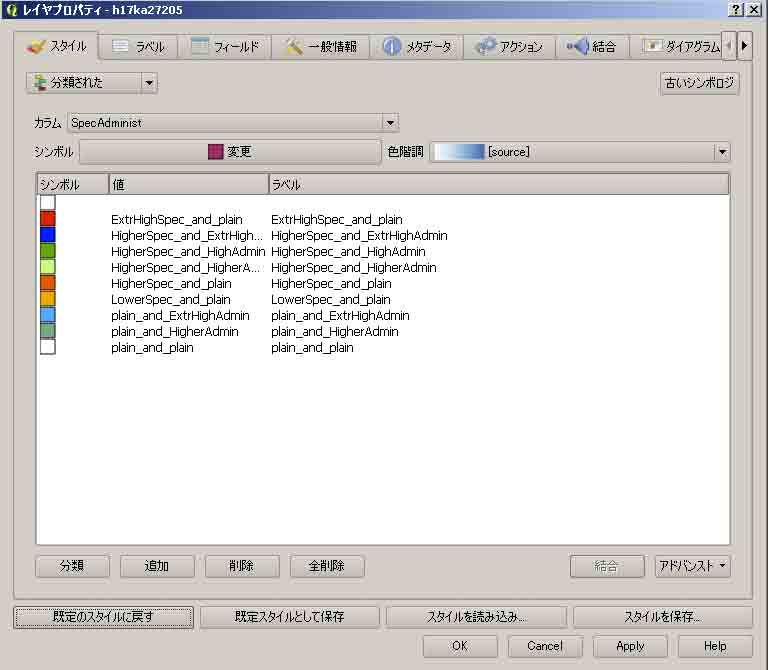
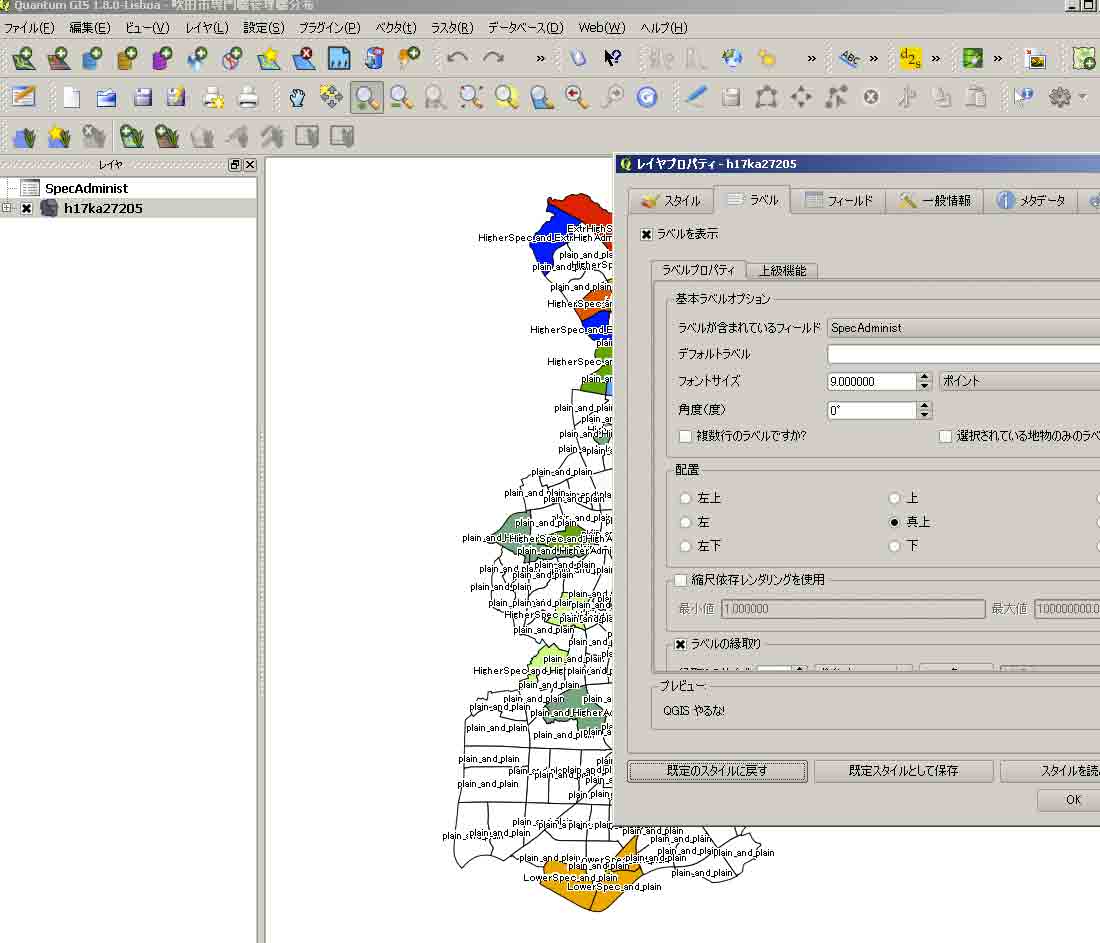
レイヤパネルの,ベクトルファイル名をクリック。してスタイルタブで,分類された,を選ぶと自動的に単色で表示される。下記のものはすでに編集済のものである。左の列の,シンボル,の正方形の中をクリックすると,種々の色に設定できる。
下の図はラベルタブで,属性テーブルのSpecAdministの列を選んで,地図を表示したものである。デフォルトラベルの欄に,ラベルと表示されているが,これは削除しておくこと。
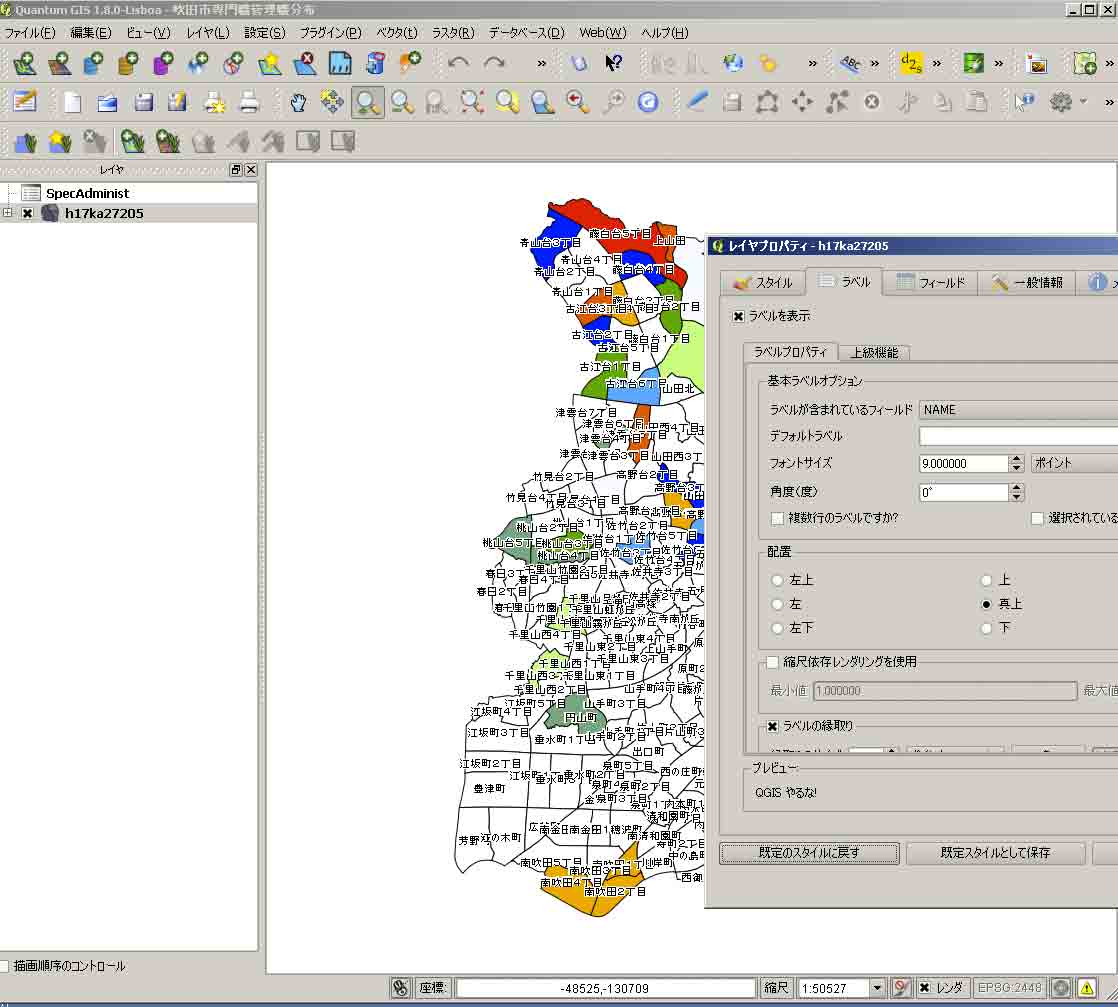
下の図は,ラベル名を,NAMEにしたものである。
下の図は,レイヤパネルで凡例を表示(command(またはcontrol)+矢印キー)し,地名表示サイズを適当にして,方位と縮尺をメーンメニューのビュー/地図装飾で表示したものである。
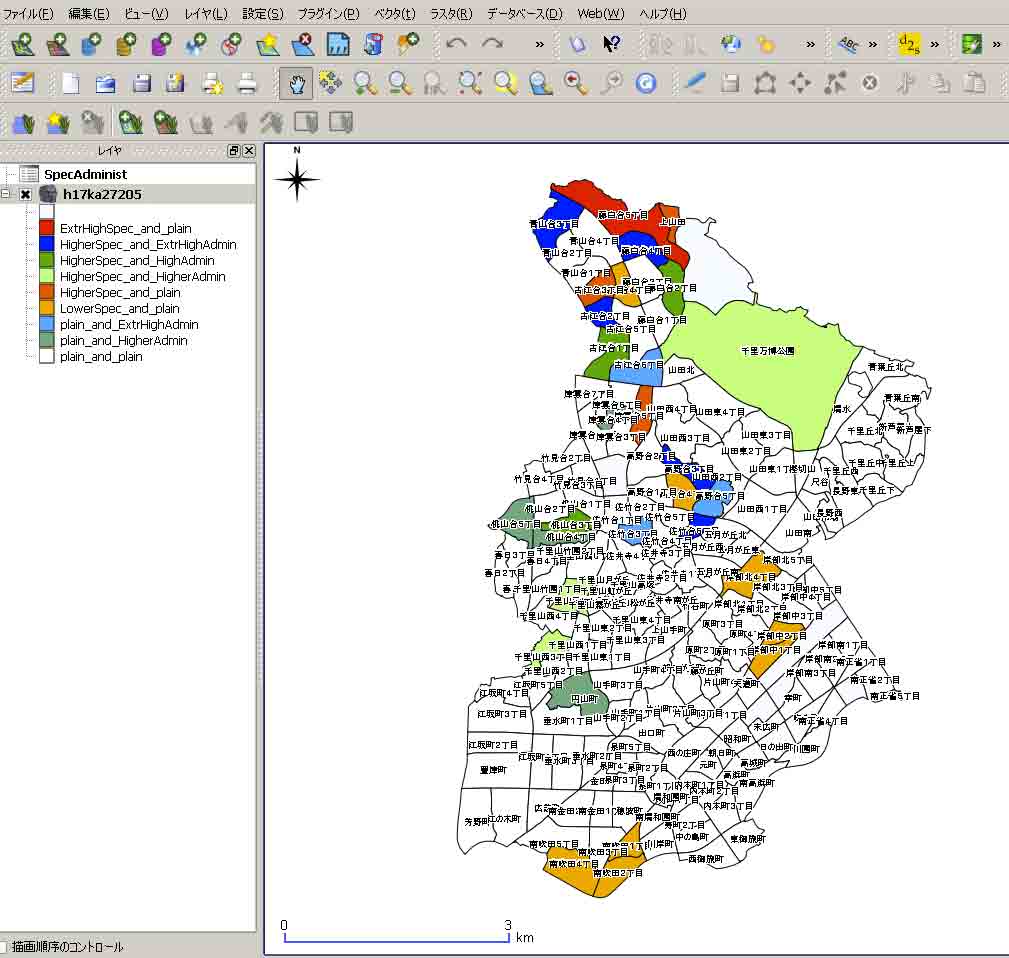
この分布図から,町丁目レベルの特色を得て,その理由を考えることになる。
8. QgisからGrassへのシェープファイル出力 Jan. 17, 2013
ここでは,Qgisからシェープ出力して,Grass-GISに取り込むまでの流れを示す。
0. この作業を実施する前に,Qgisで表示しているファイルの座標系を確認する必要がある。CS6の場合は,EPSG:2448である。レイヤでベクトルデータを選んで,ダブルクリック。タブ一般情報のCRSの指定,で可能である。
1. Qgisのレイヤでマップを選ぶと,地図が表示される。そして,control+右矢印で次の図のレイヤパネルのような凡例が表示される。
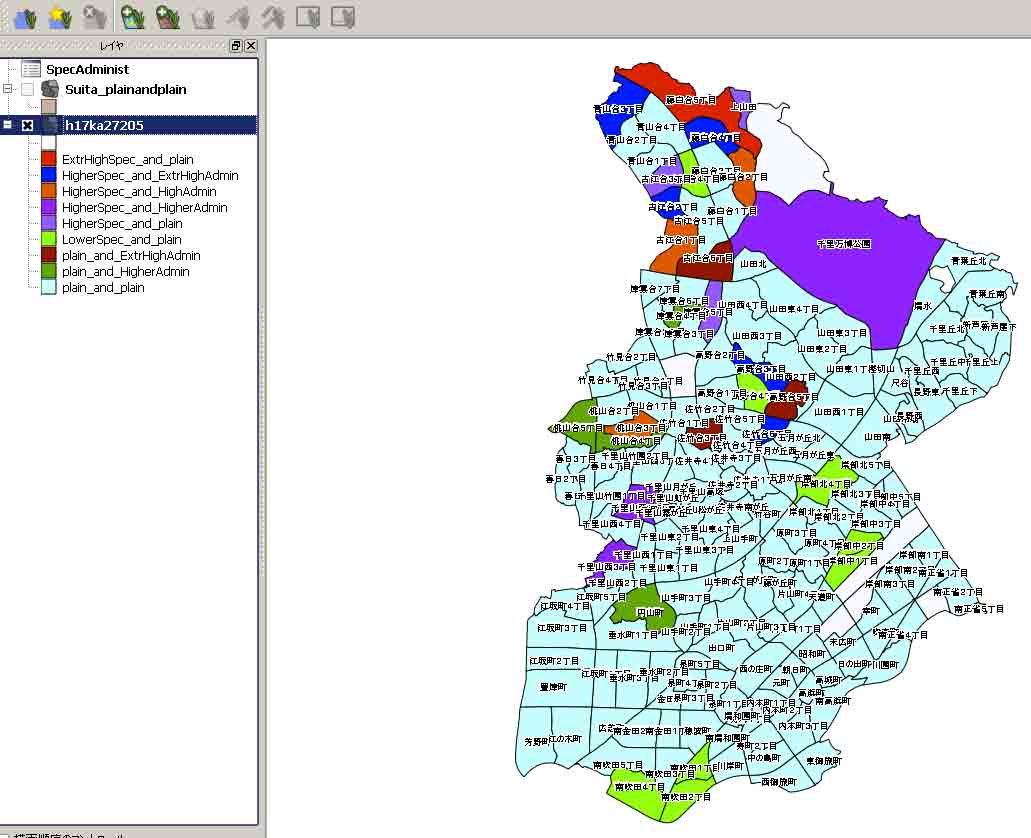
2. この例では,水色がplain_and_plainで,白抜きがその町丁目との対応数値が無いことを示す。特徴的なものがそれ以外である。
グループ分けした町丁目名を読むのに,白矢印にiがついたポインタで該当ポリゴンをクリックすると地名などを確認することができる。
赤: 専門的職業の比率が高く目立つ町丁目はExtrHighSpec_and_plainで藤白台五丁目だけである。HighSpecはなく,HigherSpecに限られる。
(出力ファイル名:ExtrHighSpec_redGroup)
紺色と橙色: 両者はAdminがExtrHighかHighで管理的職業の比率が高く,HigherSpecつまり専門的職業が比較的高い地域である。
藤白台2丁目,古江台1丁目,桃山台3丁目。
濃いまたは薄い紫色: 専門的職業が比較的高い地域。
千里万博公園,古江台3丁目,津雲台5丁目,千里山西5丁目と3丁目
(出力ファイル名:HigherSpec_purpleGroup)
茶色: 管理的職業比率が高い地域。
古江台6丁目,高野台5丁目,佐竹台3丁目,
(出力ファイル名:ExtrHighAdmin_brownGroup)
緑色: 管理的職業比率が比較的高い地域。
津雲台4丁目,桃山台5丁目,桃山台4丁目,円山町
(出力ファイル名:HigherAdmin_greenGroup)
黄緑色: 比較的専門的職業い率が低い地域。
にわけることができる。
古江台4丁目,高野台4丁目,岸辺北4丁目,岸辺中2丁目,岸辺中1丁目,南吹田1丁目,2丁目,4丁目。
(出力ファイル名:LowerSpec_lightgreenGroup)
3. アイコン群の中から,黄色の領域内に白矢印があるアイコンを選んで,そのサブメニューから,一個の地物を選択する,を選ぶ。
controlキー+クリックで複数のポリゴンを選ぶことができる。選ぶと次の図のように黄色に変化する。
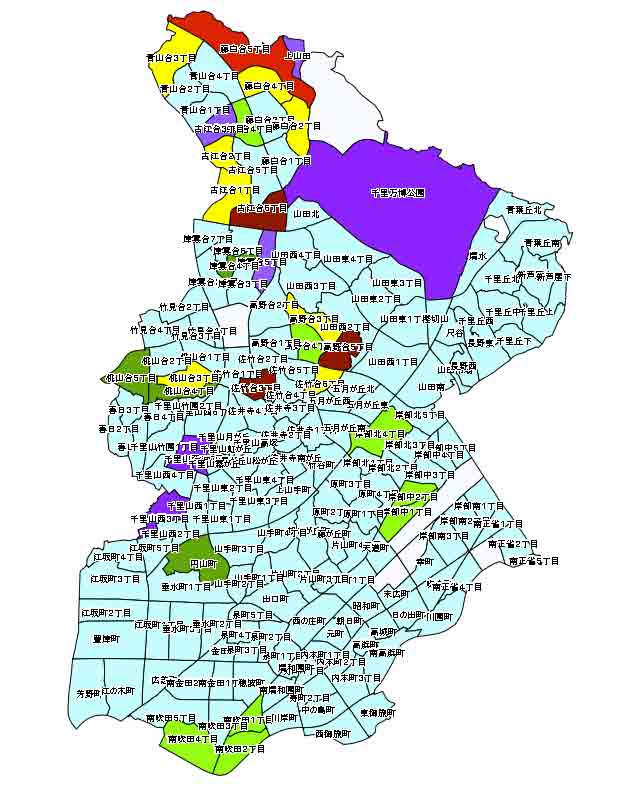
レイヤ/選択部分をレイヤファイルとして保存する,で,それぞれのグループのポリゴンをshapeファイル出力する。
4. 出力したファイルをGrassで取り込むことになる。
5. grassへのベクトルデータの取り込み
file/import vector map/ multiple formats using OGR
このパネルのタブRequiredで,OGR datasource name,Name for output vector mapを入れる。タブOptionsで,Override dataset projection (use location's projection),Extend region extents based on new dataset,Allow overwriteにチェック。
取り込んだあと,次の様に表示。
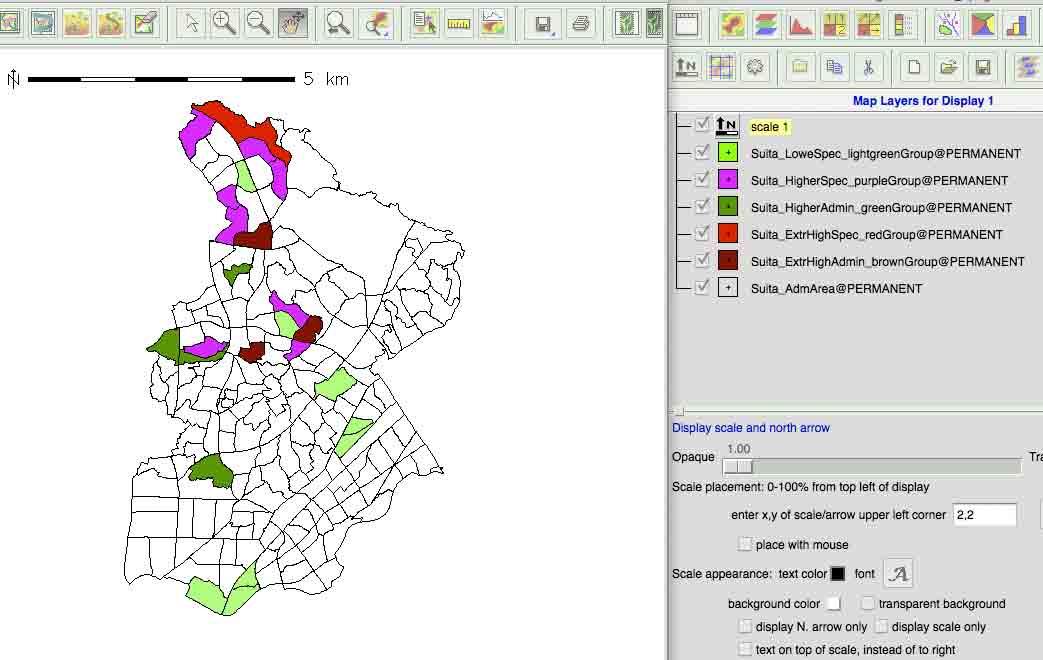
他のデータベースからのベクトルマップを表示することで,上記主題図の解釈が可能。BldAとともに表示したものを次に。集合団地か一戸建てや緑地の分布などがわかる。
マップカラーの透明度を50%にしている。
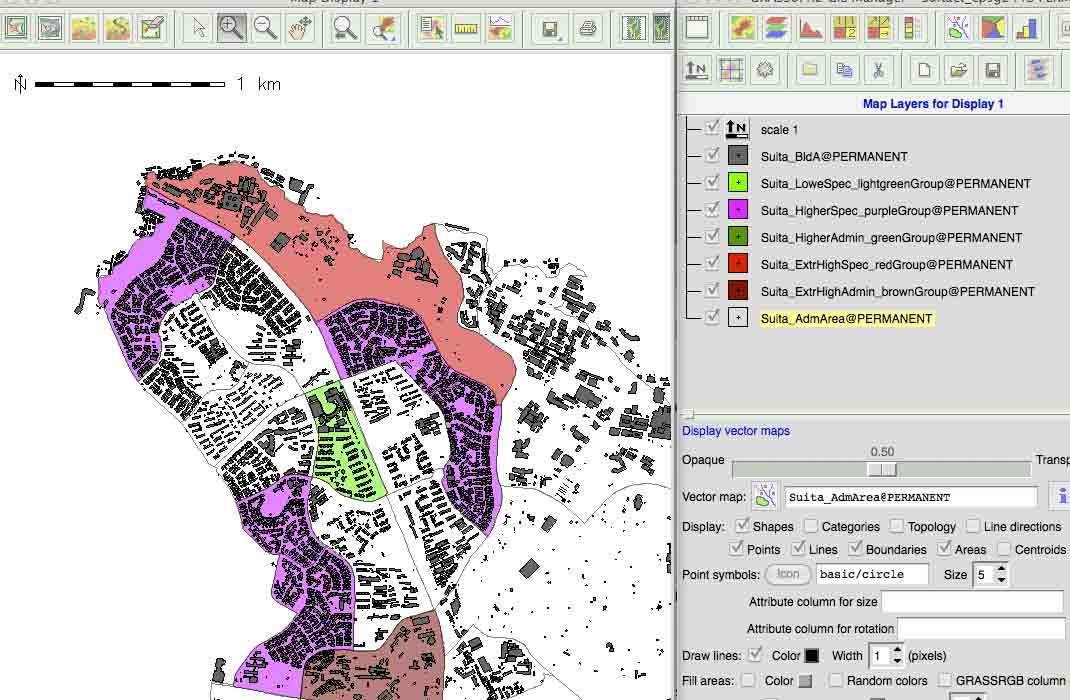
上記ベクトルデータとともに,DEMから作成したラスターマップを使うと更にリアルに現場の自然環境を表示することができる。
r.watershedを実行する。
Input-options の
Input value: minimum size of exterior watershed basinで,thresholdを3600
60px60p 5m/p
また,Raster/Terrain analysis/Slope and Aspect/のパネルで,Settingタブでdegrees,タブOutputでそれぞれ,slope, aspectを実行する。
6. そして,開析。
ラスタマップ上にベクトルマップを載せて,Grassならではの分析が可能となる。これは別途掲載する。
以 上