Dec. 9, 2003作成 Sep.13, 08 修正,Dec. 22, 09追加, Dec. 13, 15
教育的な観点から,多変量解析のフリーウェアをずっと求めてきた。フリーウェアではないが,下記のものが便利である。
柳井久江,エクセル統計 多変量解析編 オーエムエス出版 3800円
mulcel
アドインのインストール 2010の場合:Excel アドインを追加または削除する 重要 ソフトウェア開発者は、作成したアドインのインストール プログラムや削除プログラムを設計する前に、以下の手順でオートメーション プログラムのインストールや削除ができます。 Excel アドインを有効にするには [ファイル] タブをクリックし、[オプション] をクリックして、[アドイン] カテゴリをクリックします。 [管理] ボックスの一覧の [Excel アドイン] をクリックし、[設定] をクリックします。[アドイン] ダイアログ ボックスが表示されます。 [有効なアドイン] ボックスで、有効にするアドインの横のチェック ボックスをオンにして、[OK] をクリックします。 有効にするアドインが [有効なアドイン] ボックスに表示されない場合は、インストールする必要があります。 Excel アドインをインストールするには ソルバーや分析ツールなど、通常は Excel と共にインストールされるアドインをインストールするには、Excel または Microsoft Office のセットアップ プログラムを実行し、[変更] をクリックしてアドインをインストールします。Excel を再起動すると、アドインが [有効なアドイン] ボックスに表示されます。 一部の Excel アドインはコンピューターに保存されており、[アドイン] ダイアログ ボックスの [参照] をクリックしてアドインを探し、[OK] をクリックすることでインストールまたは有効にすることができます。 一部の Excel アドインにはインストール パッケージが必要です。インストール パッケージ (通常は .msi 拡張子のファイル) をコンピューターにダウンロードまたはコピーして実行することが必要な場合があります。 コンピューターで使用できないその他のアドインは、Office.com の「ダウンロードのホームページ」、またはインターネット上の他のサイトや組織内のサーバーから Web ブラウザーを介してダウンロードおよびインストールできます。必要に応じて、ダウンロードのセットアップで表示される手順に従って操作します。
ただ,これに付属するアドインソフトはエクセルの限界を当然ながら超えることができず,サンプル数やカテゴリー数が限られる。つまり,エクセルは列数が256までしか対応していないソフト(Excel 2003まで)であること,解析過程で転置行列を作るので,サンプル数やカテゴリー数ともに100個ほどしか対応しない。実験してみたらいいのだけど,疲れました。アドインは結局エクセル中のVisual Basicを使うので,マクロであっても同様の結果である。さて,余談だが,上のアドインをインストールすると,エクセルのメインメニューに,statcelの場合は統計,mulcelの場合は多変量解析というメニューが出る。これはadd-in フォルダーの両プログラムを削除しても消えない。メインメニューを初期化するには,ライブラリーフォルダから,com.microsoft.Excel.prefs.plistを削除すればいい。
エクセルアドイン工房というサイトもある。種々のプログラムがあっておもしろそうなのだが,ダウンロードの際に,お伺いを立てる必要がある。
エクセルの限界を超えて,cgiを使った群馬大学の青木先生のサイトがある。Rでプログラミングされているようだが,結果がぼくにはなじまないし,隔靴掻痒の感が強い。
MS-Windows用のものだが,というか,いっぱんの人にはこのOSがいいようなのだが,探し求めていたソフトがみつかった。秋田大学医学部社会環境医学講座のものである。公衆衛生学のことだろうが,ここの左フレームの関連リンクをクリックすると,医学統計学実習用ソフトウエア,に到達する。SPBS(圧縮ファイル),NBtest(圧縮ファイル)をダウンロードして,デスクトップ上で両圧縮ファイルのexeファイルをダブルクリックすれば,解凍される。解凍後,spbsフォルダとNBtestフォルダをプログラムフォルダ c:¥Program filesに,フォルダごと入れて,前者はspbs,後者はtap-jpnのexeファイルのショートカットを作ってデスクトップに置く。マニュアルはspbsフォルダ内のspbs.pdfなので,このショートカットも作って,デスクトップに例えば,統計処理ソフトspbsというようなフォルダにまとめて入れると使いやすい。
なお,macの場合だろうか,文字化けする。表示/テキストエンコーディング/日本語(EUC)にするとインストールの際に問題が無くなる。
なお,数量化についての基礎について,このリンクを参照してください。
このプログラムはこれ自体で,完結している。つまり,データの入力や編集機能などもある。ハードのメモリさえあれば,変数999個,サンプル数32000個に対応している。エクセル.xls(Excel 2003まで)は256列に限定(.xls)されている(Excel 2007から.xlsxは下記のように大幅に拡大されている)ので,変数がこれより多い場合は,エディターで作成すればいい。データを一つ一つ入力するようなことは多変量解析の場合,稀で,csvファイルをこのspbsに取り込むのが現実的である。
なお,Excel2007(.xlsx)から,最大列数=16,384列 最大行数=1,048,576行となった。ファイル形式はxlsx形式でなければならないので,xlsファイルの場合,xlsxで保存して,開きなおす必要がある。
ここでは数量化三類または対応分析の手法を使う。以下,○○さんのデータを使って,両手法の手順を記すこととしたい。
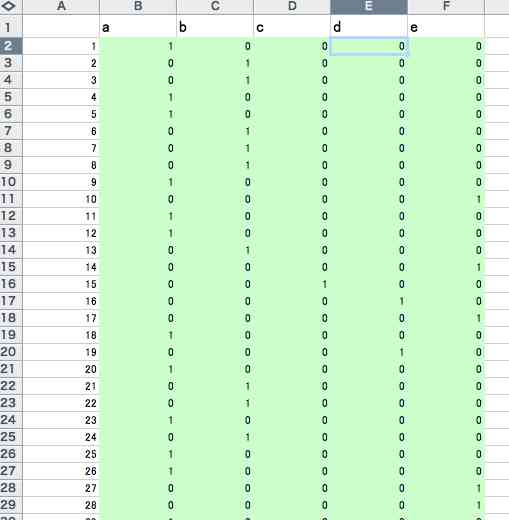
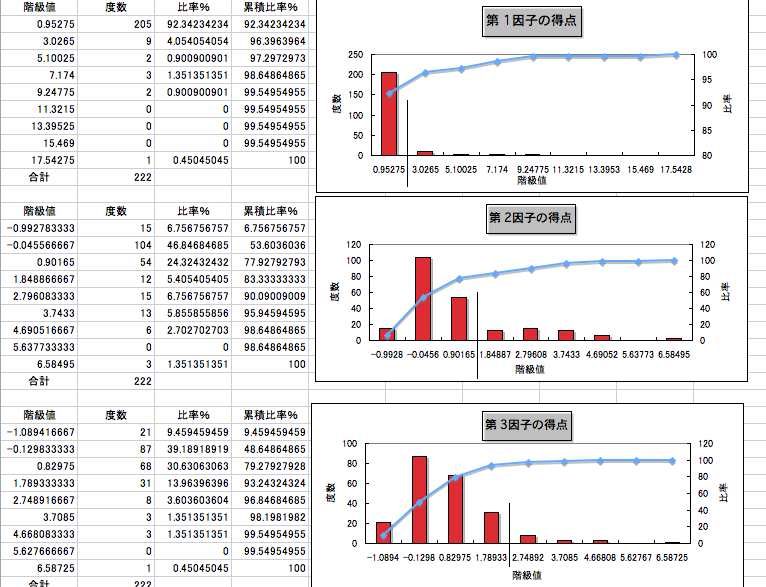
数量化三類のデータの構造は,列にカテゴリー,行にサンプルを並べる。○○さんの場合,関西新空港で海外からの旅行者から精力的にアンケートを採った。222サンプルにおよぶ。性別,年齢,常住国などの属性情報に,予定滞在日数,観光先,観光の目的などをヒアリングしている。そのうち,滞在日数アイテムについて,数量化三類をする。カテゴリー分けはa.2~4日 b.5~10 c.11~14 d.2-4週 e.1月~,の5区分である。次の図1のような表になる。Yesを1,Noを0としており,ダミー変数となっている。
図1
薄い緑色の部分が実際に使用する0と1のデータである。第1列の数字は任意に配列したサンプル(インフォーマント)番号を示している。なお,csvファイルとは,comma separated valuesの略で,たとえば,3列2行の行列を示すと,44,92,51</p> 73,53,60 </p>となる。エクセルの場合は保存時にcsv形式を指定すればいいが,MS-Wordやエディターでは,カンマと改行を意識して作成し,テキスト形式で保存すればいい。拡張子は自動で付加されない場合は,ファインダーでcsvとする。
このプログラムでは,図2のように,第1行のカテゴリー名を残したデータ表を利用する。
図2
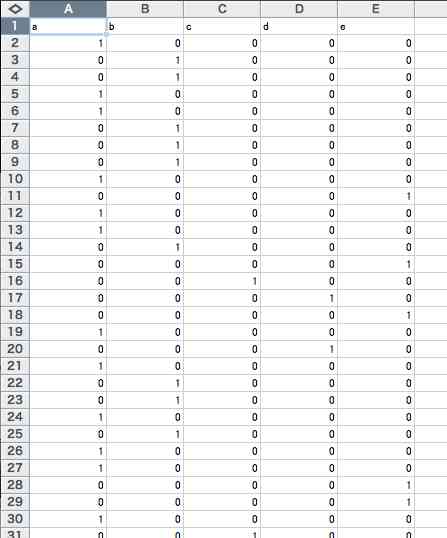
この第1行のカテゴリー名は日本語でも問題がない。全角で15字ぐらいなら問題なさそうである。
これをspbsのファイルに変換することになる。なお,spbs.pdfのp.18には,(2)データファイルExcel(csv) from/to spbs file の変換,の詳細が掲載されている。
数量化三類については,spbs.pdfのpp.70-71には,2.4. 数量化理論III類,について掲載されている。spbs.exeのショートカットファイルをダブルクリックするとメインメニューが立ち上がる。
図3
上のメインメニューの1. データ作成と編集,を選ぶと,図4が表示される。
図4
この2. データファイルEXCEL (CSV) ←→ SPBS変換,を選択する。
図5
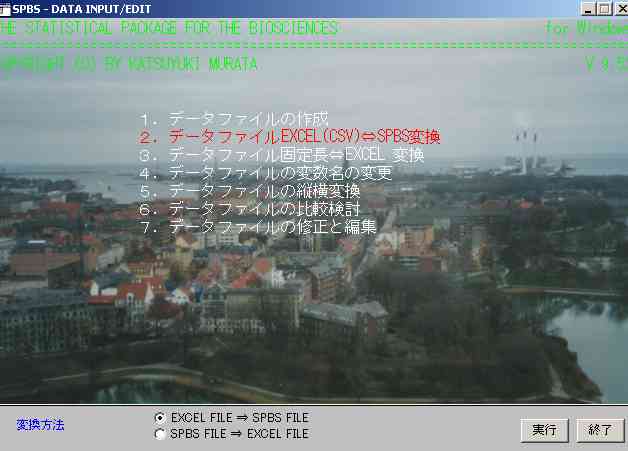
上図の最下部の欄に変換方法のオプションが出るので, EXCEL file → SPBS fileを選び,「実行」する。
図6
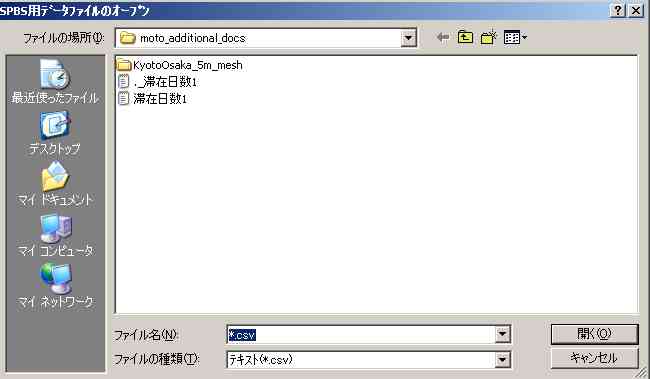
前もって,所定の場所にエクセルで作ったcsvファイルを置いて,そこにたどり着いて,ファイルを選ぶ。上図では,._滞在日数1というファイルがあるが,MacがWindowsに自動的に作るものであり,Windowsで操作する場合には,表示されない。さて,滞在日数1というファイルを選ぶと,図7のように,ファイル名が自動的に変わる。
図7
図8
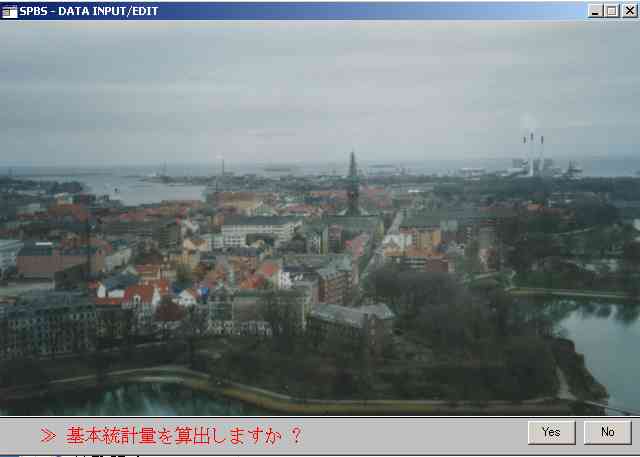
上図のように,基本統計量を算出しますか,と出る。この数量化三類の場合,意味が無いが,まあ,一応Yesとするか。
図9
その後,上図のようにメインメニューに戻る。13.主成分・因子分析,を選ぶ。この後に下の欄外に,三つのオプションがでる。主成分分析,因子分析,そして数量化三類。この場合は,最後の数量化三類を選ぶ。
図10
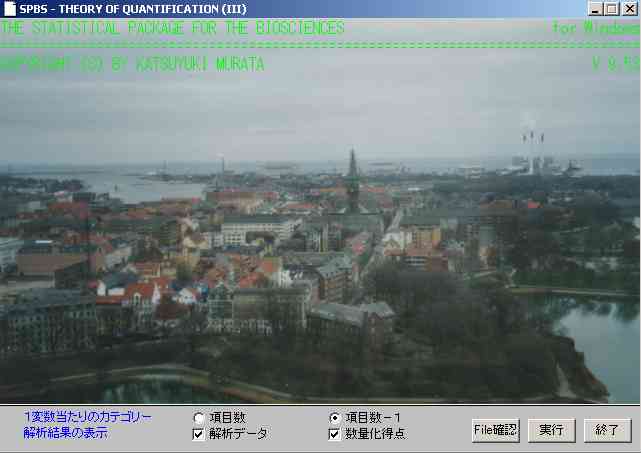
次に,上図のように,下の欄外に,オプションが表示される。上の段には,項目数か,項目数ー1(ダミー変数の場合),の選択をすることになる。前述のように,ここで使用しているデータは,滞在日数を短いものから多いものまで,5段階に分けている。いずれかがYesになる。Yesに1を宛がい,Noに0を宛がっている。このように形成された変数をダミー変数という。訪問先のように複数選択の場合で選択された場所に1を宛がっても,同様にダミー変数という。ダミー変数の場合は,項目数ー1を選ばなければならない。
通常の数量化三類,つまり,0と1だけのデータの場合,後者を選ぶ。なお,項目数,を選ぶと,SASの対応分析 correspondence analysisと同じ解が得られる。これについては後に触れる。
下段のうち,解析データ,を選ぶと, 最終的に解析で利用される形,つまり図11と同様に0と1からなるデータで表記される。すなわち,元の分析対象csvデータが0,1以外のデータからなっていても,最終的に分析可能な0と1の行列で表記する。下段のもう一つ,数量化得点であるが,これは必ずチェックする必要がある。全サンプルの因子負荷量をcsvファイルで得ることができる。
図11では変数名を1~5としているが,前述のように二バイト文字にも対応している。サンプルの値の16番目以降は省略されている。
図11
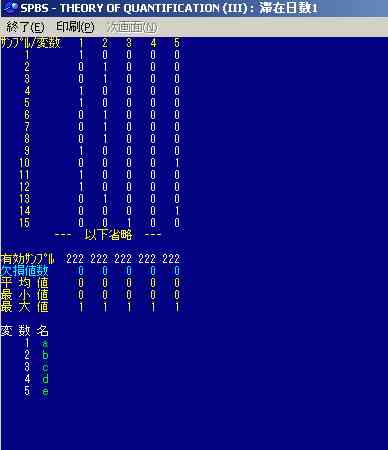
図10のところの下の「実行」ボタンをクリックすると,csvファイルの参照環境になるので,ファイル名に,滞在日数計算結果.csvというような名称のファイルを作成して,ここに結果を記録することになる筈ではある。しかしながら,そうはなっていず,このファイルには,縦一列に0,1の数値が並ぶ。つまりは分析のためのtempファイルの一種である。
図12
図13

上図 の5カテゴリー,つまり5変数が未使用となっているので,縦の矢印キーで入力位置を移動し,横の矢印キーで使用に変えるということであるが,全変数が対象なので,「全変数」ボタンをクリックすることで足りる。その結果,図14のようになる。
図14
「実行」ボタンを押すと,計算結果が表示される。
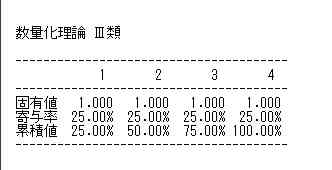
印刷メッセージが出るが,印刷してもしかたがないので止める。図15および図16の,出力された数値は,テキスト表示なので,これをエクセルファイルにコピー&ペーストして,エクセル上で,データ/区切り位置,でスペース区切りを選んで,列境界を指定するとエクセルで同様の表をえることができる。
図15
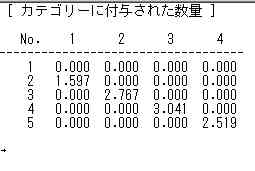
下記は固有ベクトルに対する各カテゴリー1乃至5の射影,つまり因子負荷量である。
図16
この後に,各サンプルの因子得点をファイルで得ることができる。この結果が無いと,意味がない。
「サンプル得点をファイルに保存しますか」とメッセージが出るので必ずYesとすること。他の関連ファイルを格納しているフォルダに適当な名前をつけて保存すること。
このデータに基づいて各主成分ベクトルごとにソートして,サンプルをグループ化することができる。下の1.2.3セクションを参照のこと。
次の図は,以上の分析過程で生成されたファイルである。 この分析はアイテムが滞在日数一つで,カテゴリーが5区分されたものである。
図18
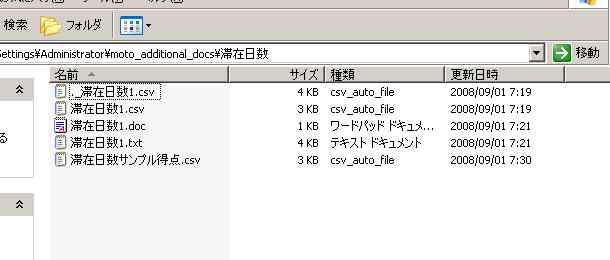
以上のファイルについて簡潔に示す。前述したように,._ファイルはMacが自動的に生成するもので,分析とは直接関係ない。やはり前述のように,滞在日数1.csvはエクセルで作ったcsvファイル。 最初にspbs用のファイルに変換した訳だが,その際に作成されたのが,滞在日数1.docと滞在日数1.txtである。
図19 滞在日数1.csv

図20 滞在日数1.doc
上図には,カテゴリー数5,カテゴリー名,サンプル数222が表示されている。
図21

上図は,カテゴリー名が省かれた0と1の縦データとなっている。
因子得点の方は,前述のようにファイルで取得できる。その例を次にしめす。
図22 各サンプルの因子得点のファイル
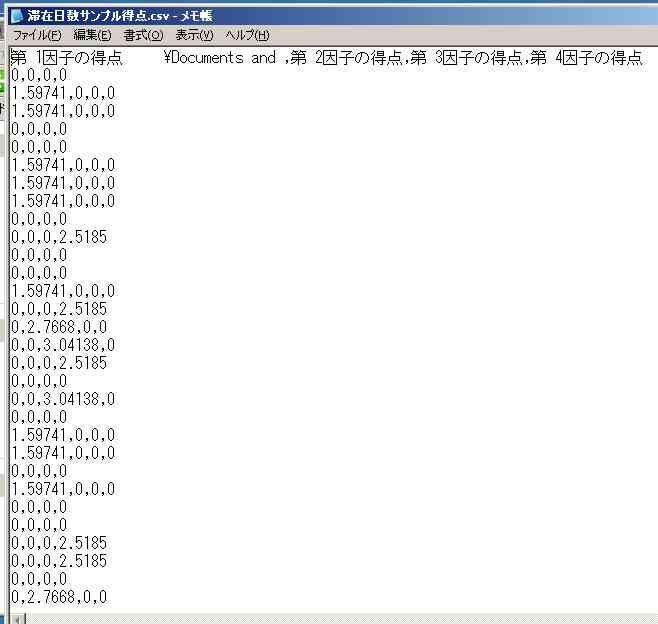
この因子得点または負荷量の符合は,使用するアルゴリズム,パソコンのアーキテクチャーなどによって全体が変わる場合がある。因子分析(主成分分析)と同様,この符号は相対的なものである。全ての符号を逆転させても解釈上に差は生じない。
一応の計算結果がでた。プログラムspbsに使い方は一応,説明できた。
このデータはあまりに単純なので,結果は多変量解析するほどのものではない。1.2.3の例では,より複雑なものを提示する。
先の計算結果のうち,図22に示したサンプル得点の結果は,図23のF列以下に繋ぐことになる,個々のサンプルの属性情報がB~E列に示されているので,各主成分ごとに降順にソートしてサンプルを分類する。サンプルごとに個々の主成分に対する得点には違いがあり,サンプルの個性をみつけることができる。属性情報との対応関係を見れば,滞在予定日数の相関を知ることができるであろう。
図23
なお,勘違いがあるかも知れないので,一応,注意する。カテゴリー名を別にして,分析対象のデータの枠内では,数値のみ対応する。アルファベットなどが入る場合,むっしーされる。
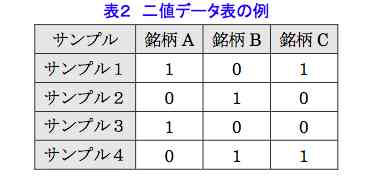
先の大隅さんの図をつかって説明したい。データ表は,図24のように,行はサンプル,列はカテゴリーからなる。地理行列も同様,たとえば都道府県は行で,人口や工業生産額は列になる。図24では,日本酒の銘柄で,サンプル1以下はインフォーマントを意味する。サンプル1は,銘柄AとCが好きだということである。好きか嫌いだから1と0で表せる。これは数量化三類の対象になる。0,1はダミー変数だ。
図24
次の例は,多変量解析をする意味がある構造のデータである。普通作られるのはこの種のものである。項目にIとJがある。項目Iは,食堂の名称で,項目Jはその食堂の評価である。項目つまりアイテムIは,10 件からなる。例えば回答者1284は,いりふね,ラ・マレ,かりやなどが好きである。ここで見えている項目Jは3件からなる。回答者1284は量が多いから,好きのようだ。
すきな食堂と理由がセットになっている。データ値はすべて,0と1からなっている。
図25
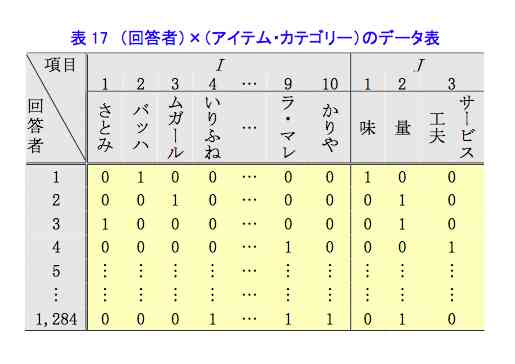
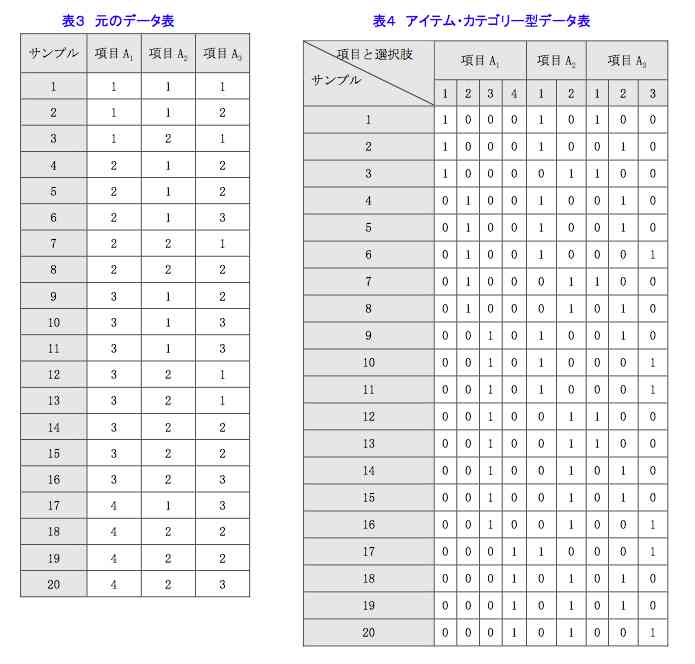
図26は,元のデータ表(表3)から,アイテム・カテゴリー型データ表(表4)を作成した例である。項目A1は4種のカテゴリー,項目A2は2種,項目A3は3種のカテゴリーからなることがわかる。表3のサンプル2の項目A3の値は2であるが,表4を見ると,項目A3のカテゴリー2の1に対応している。
図26
最初から,上の表4を書けばいいのであるが,0と1のデータ表のアイテムの区分はどうすればいいのだろう。実は,プログラムspbsは,表4の0と1のデータから分析する方式を持っていないようである。表3のデータを入力して,応答分析をすれば,表3から表4を作成する。
繰り返すが,spbsは,アイテムが2種類以上の場合には,カテゴリーは異なる数値で表現する。名義尺度でもそうである。数字の種類は全部で10個である。つまり,カテゴリー数の最大値は10となる。数値を当てはめるならば,1~9と0である。通常,0 は使わないだろうから,9種ということになる。これ以上ある場合は,何らかの整理をすればいいだろう。
上の表3と表4の例では解決できないデータがある。複数のアイテムがあり,アイテム内でも複数の回答があるという例はよくある。多少,分析結果の解釈が難しいかもしれないが,まとめて数量化三類の分析を実施することは可能である。
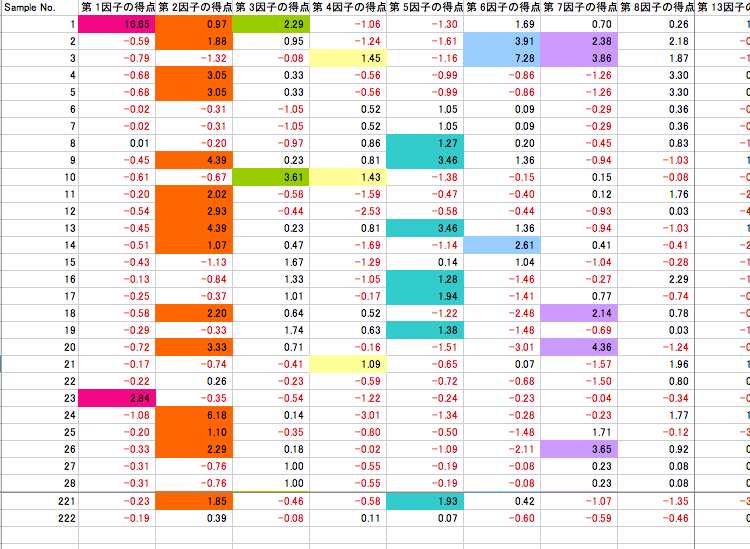
ここに示す例はやはり○○さんのものである。旅行目的a-dの4列,旅行の興味分野a-e5列,行く先a-g7列として,全部で16列,つまり16変数がある。サンプル数は222である。変数の具体的な内容はwordファイルにまとめている。ダミー変数で示した分析対象データはcsvファイルにまとめている。
固有値と寄与率 図27は出力された固有値,寄与率などの表(テキスト)を,エクセルファイルにコピー案でペーストして,エクセル上で,データ/区切り位置,でスペース区切りを選んで,列境界を指定して得た表である。
第7主成分まで採用すると,寄与率の累積値が76%になるので,一応,第7主成分までを評価することにした。
図27

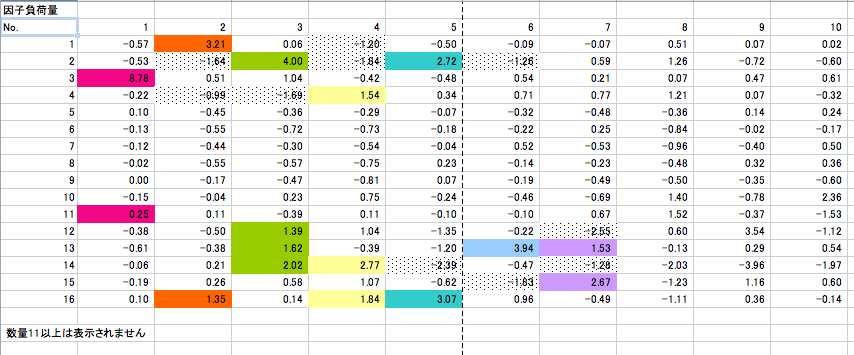
因子負荷量 図28にみられるように,第7因子までについて,因子負荷量の高い値に色づけした。各因子の色を適当に設定した。変数の数は16で,変数と主成分ベクトルの関係がこの表に表示されている。例えば,第Ⅰ主成分と変数3は非常に高い相関を持っていることになる。
変数の数が多くなると因子負荷量の値の大小を探すことが困難になるが,その方法は,次の因子スコアの整理,に示す方法を使えばいい。
図28
0. csvファイルをエクセルファイルに変更する。これは大変重要で,次に述べる作業結果が保存されないことになる。筆者の失敗を踏まえて。
1. 第1列にサンプル番号を追加。
2. スプレッドシートでA1セルを左上端に置いて,右下方向の比較的隅に近いところで,「ウィンドウ枠の固定」をする。その際, 寄与率の累積値が70%ほどまでをカバーする主成分ベクトルが十分に利用できるようにすること。
3. 書式/セル,で,小数点以下2桁の表示,マイナス値は赤で表示してプラスとマイナスを見やすくする。
4. スプレッドシートでデータの右下隅が見えるように,スクロールする。ウィンドウ枠が固定されているため,必要な列と行は全部見えている。
5.データの右下隅をクリック,シフトキーを押しながら,A1セルをクリック。これで全体を選ぶ。
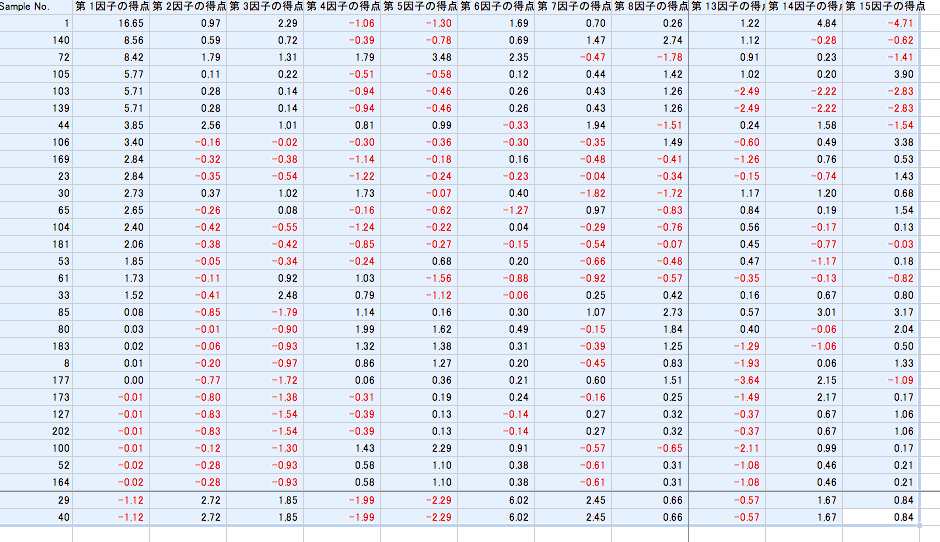
6. データ/並べ替え/で,まずは「第1因子の得点」を最優先されるキーに選んで降順にする。もちろん範囲の先頭行はタイトル行のボタンを選んでおく。
7. そうすると第1因子の数値が降順に並ぶ。sample no.1の16.65が最大値で次はno.140の8.56が続く。図29がその結果である。
図29
どこまでを第1因子に属させるかの判断はかなり恣意的なものである。因子負荷量については,第7因子までを採用している。それぞれに色を設定した。図に示したものである。第1因子は赤である。
さて,恣意性をできるだけ小さくするために,それぞれの因子についてヒストグラムを作ることになる。
8. ヒストグラムを図30のように作成する。正規分布図でモードの区分をするというより,多数の因子スコアの小さな値をもつものは因子に関連がないと考える立場である。図30のように,それぞれを大きく2区分して,区分値よりも大きな因子スコアに,因子負荷量と同じ色で着色する。
図30
9. 個々の因子について,8を実行して,Sample No.の昇順に並べた結果が図31である。
図31
10. 図31に見られるように,色づけができないサンプルもある。トップ7の主成分だけではなく,残りの主成分でも色づけができないものもある。この分析例では調査での3アイテムが利用されたが,このアイテムについては,その他になってしまうサンプル群だと考えることになる。
なお,上に上げたスクリーンショットの元のエクセルファイルをここに示す。これをどのように解釈するかは,調査した○○さんであって,私ではない。
1.因子負荷量から,各主成分の意味を変数から理解する。2.因子得点から主成分に対する高い得点分布を見て,サンプルの特色を理解する。この際に他のサンプルの属性から各主成分の意味をフィードバックして推定することになる。
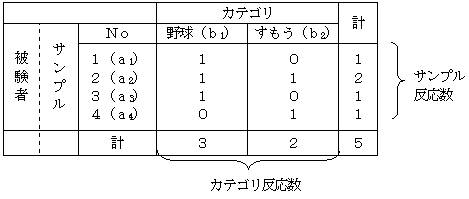
次のサイトがわかりやすくこの手法を説明している。 http://gucchi24.hp.infoseek.co.jp/SUR3.htm 本演習室のPCにはSPSS統計パックがインストールされている。この結果は信頼性の高いものであるが,自宅で実施できないので,ここではエクセルで利用可能な方法を示す。 数量化Ⅲ類では,質的なカテゴリーとサンプルを同時に,数量化して,両者の相関を最大にするように両者に数値を与える方法である。具体的には,この例にあるように,4名の被験者について,野球と相撲について好きか嫌いかをまとめた表データを分析するのにこの方法は適している。
柳井久江のエクセル統計:実用多変量解析編(オーエムエス出版,2005),の場合,次の例がある。
この計算結果は次のようである。
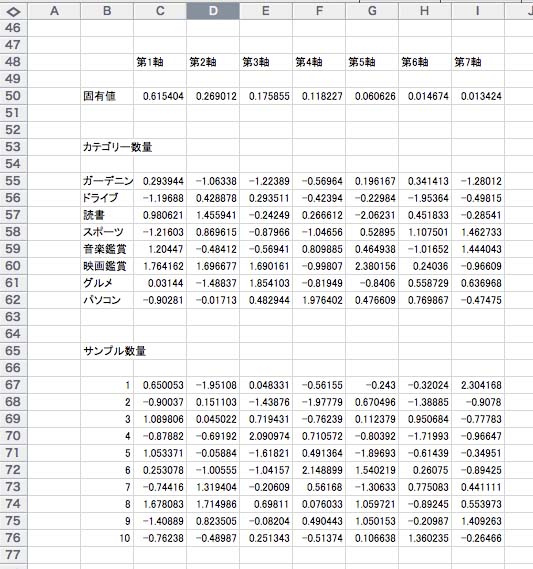
上の表で,第Ⅰ軸~第7軸(7つの固有ベクトル)が抽出されているが,左ほど重要な主成分になっている。固有値はそれぞれの固有ベクトルに対する正射影である(1.0000の場合は一致)。左から右へ固有値を足して,その合計値で個々の固有値を割って100倍すると,寄与率を求めることができる。左から右に累加してゆくと累積寄与率を得ることができる。通常,70%に達すれば,それより低い主成分軸は省略してよい。 カテゴリー数量の表と,サンプル数量の表が見えるが,通常,それぞれ,カテゴリースコア(得点),サンプルスコアという。この評価法については授業で実施する。そして,余暇行動と女性10名を分類して,記述モデルを求める。この過程で,散布図を利用することができる。 この分析結果は,数字になっている。つまり質的データが量的データに変身したわけだ。この数値を使えば,クラスター分析の対象になって,より客観性の高い分類が可能になる。クラスター分析については,また追加する。
因子分析も多用される多変量解析法の一つである。柳井の例題6の例とその計算した結果のエクセルファイルを次に。例題6
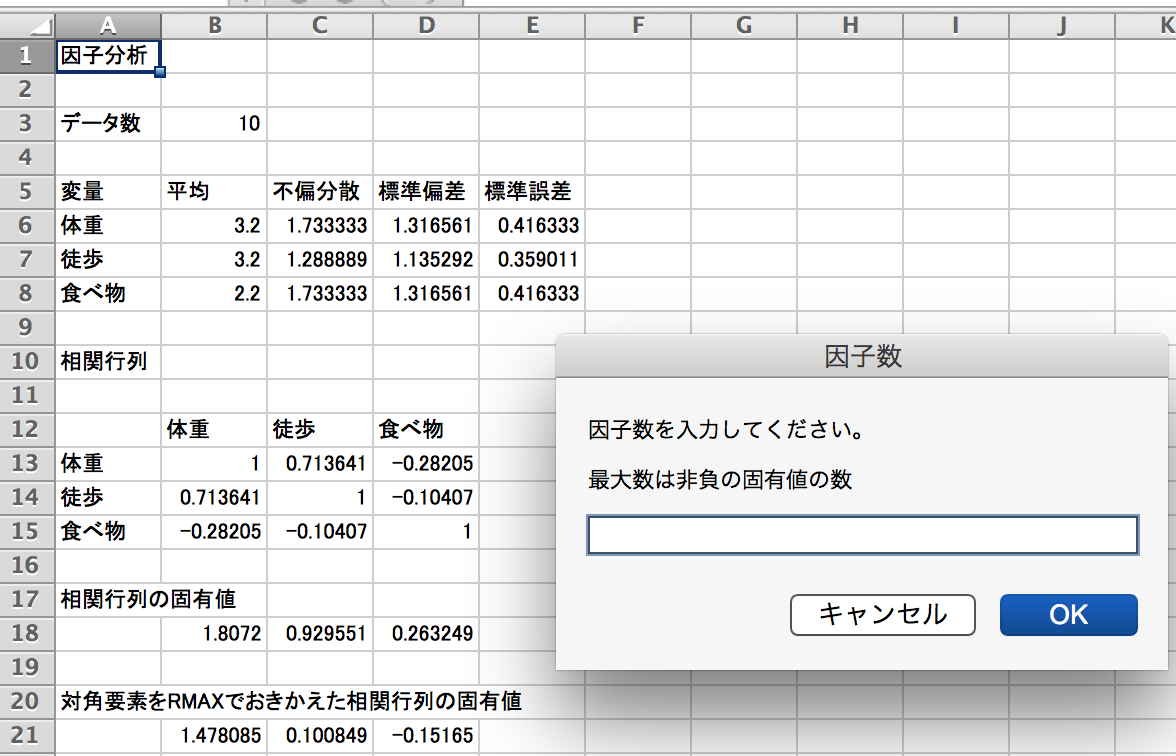
Windowsでは計算時のパネルが文字化けするので次にスクリーンショットを示す。
データ範囲は列挙データの部分を選ぶ。ケース番号は選ばない。
出力データが多いので,出力範囲は別のスプレッドシートの方がいいだろう。
データフォームは列挙データ,条件はSMC法,解法は反復解法,回転にはチェックを。

このパネル入力後,相関行列の固有値が出力される。この結果をみて,有効な因子数を判断し,その数をアラートの欄に入力することになる。RMAX法の例を次にしめす。この計算結果は,RMAXとした三枚目のスプレッドシートに記している。なお,RMAX法とは,因子分析において、共通性(共通因子で説明される分散)を推定する方法の1つ。 推定したい変数が関与する相関係数のうち、大きさが最大のものを、その変数の共通性と考える方法。
なお,因子分析の簡便な説明と分析実例をつぎにみることができる。
石川 慎一郎, 2009. 因子分析における因子抽出法間の比較 ―日本人英語学習者の語彙学習方略データを利用して― 統計数理研究所共同研究レポート, No. 232, pp. 25-38.
以 上
補遺: Mac用である。ただ,Excelを使うため,サンプル数は100件ほどに限られる。 杉山和雄・井上勝雄編,1997 2nd ed., EXCELによる調査分析入門 企画・デザインのためのツール集. 海文堂, 168p. Mac版 3.5 inch FD付. 3300円.
この本は,アンケートの考え方を理解する上で,参考になると思います。アンケートの低劣性をかなり改善してくれるように感じます。
日本デザイン学会方法論研究部会のweb-siteに上の本のプログラムが掲載されていてダウンロードすることができました。今はもう空き。